¶ Cluster 생성
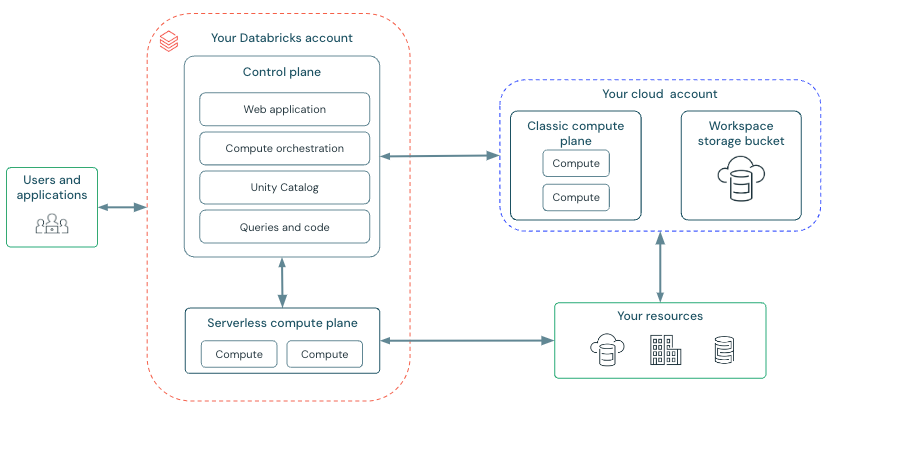
¶ High-level architecture
¶ Cluster 생성
- Workspace 에 로그인합니다.
- 좌측 메뉴 Compute > Create compute
- terraform 으로 cluster 생성도 가능합니다.
¶ Policy
- cluster 생성시 user 가 지정할 수 있는 option 제한 rule set 입니다.
- 특정 policy 에 접근할 수 있는 user 또는 group 을 제한하는 ACL 이 있습니다.
- 기본적으로 Personal Compute policy 접근 가능합니다.
- 해당 policy 가 안보인다면 관리자에게 문의합니다.
- Cluster policy 문서
¶ Multi/Single node
- Spark worker 가 여러개인지 1개인지
¶ Cluster Access Mode
| Access mode | Visible | UC 지원 | 지원 언어 |
|---|---|---|---|
| Single user | 항상 | O | Python, SQL, Scala, R |
| Shared | 항상(premium plan 필요) | O | Python, SQL, Scala |
| No isolation shared | admin console 에서 user isolation 을 실행해서 cluster 를 숨길 수 있음 | X | Python, SQL, Scala, R |
| Custom | 예전 버전에서 만들었을 경우 | X | Python, SQL, Scala, R |
¶ Performance
¶ Databricks runtime version
- https://docs.databricks.com/runtime/index.html
- Apache Spark 가 포함되어 있습니다.
- Cluster 생성시 runtime version 을 설정 가능합니다.
- Standard
- Apache Spark 가 포함되어 있습니다.
- ML
- Apache Spark 와 mlflow 가 포함되어 있습니다.
Databricks Runtime 을 줄여서 DBR 이라고 합니다.
¶ Photon 가속
- DBR 9.1 LTS 이상에서 사용 가능합니다.
https://www.youtube.com/watch?v=pNn5W4ujP3w
- C++ 로 만들어진 새로운 Spark 실행 엔진입니다.
- operator(+, <, ...) 마다 최적화합니다.
- null check 를 먼저 진행합니다.
- stage(Scan, Filter, Aggregation) 마다 lazy evaluation 으로 최적화합니다.
- read 3.3배, write 2~3배, tpcds 4배정도의 속도가 향상되었습니다.
경험으로는
- 단순히
spark.read.parquet("...")만 실행해도 photon 을 켜는 경우 2배 이상 속도 향상이 있었습니다. - 그러나 그만큼의 추가 비용 이 발생하지만, EC2 사용시간이 줄어들어서 전체적인 비용이 절감될 수 있습니다.
¶ Cluster node type
- Cluster 구성: 1개 Driver + 0개 이상 Worker
- 기본으로 driver, worker 는 같은 instance type 을 사용하도록 되어 있으나, 변경 가능합니다.
¶ Driver node
- Cluster 와 연결된 모든 notebook 상태 정보를 유지합니다.
- SparkContext 를 유지/관리합니다.
- notebook 이나 library 에서 실행하는 command 를 해석합니다.
- Apache Spark Master 를 실행합니다.
- 기본 instance type 은 Worker node 와 같습니다.
df.collect()같은 작업은 driver node 의 많은 memory 를 필요로 합니다.
연결된 모든 notebook 의 상태 정보를 유지하기 때문에 사용하지 않는 notebook 은 detach 하기를 권장합니다.
¶ Worker node
- Spark Executor 이며, cluster 에 필요한 다른 서비스를 실행합니다.
- Apache Spark 에서는 executor 개수를 설정할 수 있었으나, Databricks Spark 에서는 worker node 1개당 executor 1개만 실행됩니다.
- 그래서 databricks architecture 에서는 executor 와 worker 를 같은말처럼 사용합니다.
¶ Worker node IP 주소
- 같은 workspace 내 여러 cluster 간 isolation 을 위해서 2개의 private ip 를 가지고 실행됩니다.
- primary private ip: 내부 traffic 을 호스팅합니다.
- secondary private ip: cluster 내 통신을 합니다.
¶ GPU Instance type
- Deep Learning 같은 고성능 작업이 필요한 경우에 사용할 수 있으나, AWS 관리자에게 문의해야 할 수 있습니다.
- AWS Graviton 을 지원합니다.
¶ Autoscaling Cluster size
- worker 개수를 fix 하거나 min, max worker 개수를 지정할 수 있습니다.
- 작업의 크기가 일정하다면 fix 를 권장합니다.(auto scaling 에 시간이 소요됩니다.)
spark-submit job 에서는 auto scaling 사용이 불가합니다.
¶ autoscaling 작동방식
- 2단계로 min 에서 max 로 확장됩니다.
- cluster 상태가 idle 이 아니어도 shuffle file 상태를 확인해서 scale in 됩니다.
- 현재 node 의 percentage 기반으로 scale in 됩니다.
- job cluster 에서 40초동안 사용되지 않으면 scale in 됩니다.
- all purpose cluster 에서 150초동안 사용되지 않으면 scale in 됩니다.
spark.databricks.aggressiveWindowDownS라는 Spark 설정으로 down scaling 결정 빈도를 초 단위로 지정 가능합니다.- max: 600
- 보다 더 자세한 내용은 여기를 참고합니다.
instance pool 사용시 pool 의 idle instance 개수, capacity 에 따라 cluster 생성이 성공할 수도, 실패할 수도 있습니다.
| EVENT TYPE | TIME | MESSAGE |
|---|---|---|
| RESIZING | 2023-11-06 10:16:17 KST | Autoscaling from 2 down to 1 workers. |
| RESIZING | 2023-11-06 10:13:42 KST | Autoscaling from 3 down to 2 workers. |
| RESIZING | 2023-11-06 10:11:02 KST | Autoscaling from 5 down to 3 workers. |
| UPSIZE_COMPLETED | 2023-11-06 10:08:36 KST | Compute upsize to 5 nodes completed. |
| RESIZING | 2023-11-06 10:03:57 KST | Autoscaling from 1 up to 5 workers. |
| DRIVER_HEALTHY | 2023-11-06 09:06:38 KST | Driver is healthy. |
| DRIVER_HEALTHY | 2023-11-06 09:06:36 KST | Driver is healthy. |
| RUNNING | 2023-11-06 09:06:02 KST | Compute is running. |
| STARTING | 2023-11-06 08:59:30 KST | Started by haneul.kim@data-dynamics.io. |
¶ Autoscaling Local Storage
- cluster 생성 시 고정된 수의 EBS volume 을 할당하지 않을 때 사용합니다.
- Spark worker 에서 사용 가능한 disk 용량을 모니터링 하다가 disk 용량이 적어지기 전에 새로운 EBS volume 을 자동으로 attach 합니다.
- EBS volume 은 instance 당 최대 5TB 총 disk 용량까지 attach 가능합니다.
- instance 가 return 될 때 EBS volume 도 detach 됩니다.
- 실행중일 때는 detach 되지 않습니다.
- EBS 사용량을 줄이기 위해서는 AWS Graviton instance type 을 사용하거나 자동 종료 옵션 사용을 권장합니다.
¶ Local disk encryption
- shuffle data 또는 temp data 같은 local 에 attach 된 disk 에 쓰는 data 를 암호화 할 수 있으나, 성능이 느려질 수 있습니다.
- Clusters API 를 사용해야 가능합니다.
¶ Cluster tag
- 리소스 비용을 쉽게 모니터링할 수 있습니다.
- VM, Disk Volume 같은 Cloud Resource 와 DBU Usage report 에 적용됩니다.
- Cluster pool 에서 시작된 resource 의 경우, DBU Usage report 에만 적용되고 Cloud Resource 에는 전파되지 않습니다.
Name이라는 tag 를 추가하면 안됩니다.- ISO 8859-1 (latin1) 문자만 사용 가능하고, 그 외 문자는 무시됩니다.
- https://docs.databricks.com/administration-guide/account-settings/usage-detail-tags-aws.html
¶ Availability zones
- Cluster 의 AZ 를 지정 가능합니다.
- 기본값은 auto 입니다.
- auto 로 지정하고 AWS 에서 용량 부족 오류를 반환하는 경우 다른 AZ 에서 재시도합니다.
- 특정 AZ 를 선택하는 것은 reserved instance 를 구매한 경우에 유용합니다.
¶ Spot instances
- spot instance 를 사용할지 여부와 spot instance 를 시작할 때 사용할 최대 spot 가격을 해당 ondemand 가격의 백분율로 지정할 수 있습니다.
- 기본적으로 최대 가격은 ondemand 가격의 100%입니다.
¶ EBS volumes
Instances 탭에서 EBS Volume type 에서 선택합니다.
¶ Default EBS volumes
모든 Worker 에 provision 합니다.
- Host OS 및 Databricks 내부 서비스에서 사용하는 30GB 의 암호화된 EBS instance root volume
- Spark Worker 가 사용하는 150GB의 암호화된 EBS container root volume
- Spark service 및 log
- (HIPAA만 해당) Databricks 내부 service 에 대한 log 를 저장하는 75GB 의 암호화된 EBS worker log volume
¶ Add EBS shuffle volumes
- General purpose SSD 를 선택합니다.
- 기본적으로 Spark shuffle 의 output 은 local disk 를 사용합니다.
- data 가 커져서 shuffle 이 많이 발생하는 경우, 용량이 부족해지는 현상을 방지할 수 있습니다.
- Ondemand 및 Spot instance 모두 EBS Volume 을 암호화 합니다.
¶ Optionally encrypt Databricks EBS volumes with a customer-managed key
- customer managed key 로 EBS volume 을 암호화할 수 있습니다.
- https://docs.databricks.com/security/keys/customer-managed-keys-storage-aws.html
¶ AWS EBS limits
- service quota 에 의해 제한된 경우, 관리자에게 문의합니다.
¶ AWS EBS SSD volume type
- gp2 와 gp3 중에서 선택할 수 있습니다.
- Databricks 에서는 비용절감을 위해 gp3 를 권장합니다.
¶ Spark configuration
- Apache Spark 설정을 추가할 수 있습니다.
¶ Retrieve a Spark configuration property from a secret
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}spark.password {{secrets/acme-app/password}}
¶ Environment variables
- 미리 정의된 환경변수가 있습니다.
¶ Cluster log delivery
- Driver node, Worker node, event log 를 저장할 경로를 지정할 수 있습니다.
- 5분마다 저장됩니다.
- Cluster 종료시까지 생성된 모든 log 전달을 보장합니다.
- 경로를
dbfs:/cluster-logs로 지정하고 ClusterId 가0630-191345-leap375라면,dbfs:/cluster-log-delivery/0630-191345-leap375에 저장됩니다.
¶ S3 bucket destinations
- S3 로 지정한 경우, bucket 에 access 할 수 있는 Instance profile 로 cluster 를 생성해야 합니다.
PutObject,PutObjectAcl권한이 필요합니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<my-s3-bucket>/*"
]
}
]
}
¶ 실습을 위한 Cluster 생성 (예시)
Cluster 생성은 Workspace Admin 이어야 가능합니다.
- Name: 적절한 Cluster 이름 지정
- Policy: Unrestricted
- Multi node
- Access mode: Single user
- Databricks Runtime Version: 15.4 LTS (LTS 중 최신버전 선택)
- Worker type: m4.large, Min: 2, Max: 8
- Driver type: m4.large
- Enable autoscaling: true
- Enable autoscaling local storage: false
- Terminate after
30minutes of inactivity - Instance profile: None
- Tags: 필요한 경우 지정
- 그 외 수정사항 없음
- 생성을 누르면 Cluster 가 자동으로 시작됩니다.
¶ References
- https://spark.apache.org/docs/latest/cluster-overview.html
- https://docs.databricks.com/clusters/create-cluster.html
- https://docs.databricks.com/clusters/configure.html
- https://docs.databricks.com/administration-guide/clusters/policies.html
- https://docs.databricks.com/administration-guide/account-settings/usage-detail-tags-aws.html!